Universal Ink Model
本仕様では、言語やプラットフォームに依存せず、電子ペンやスタイラス、あるいはタッチ入力によって取得したデジタルインクデータを再現および加工するためのデータモデルを定義します。 このデータモデルは、本ドキュメント内で"Universal Ink Model"と呼ばれています。
インクモデルの主な特徴は次のとおりです。
- 他のシステムとの間で標準化されたインターフェースを定義することで、相互運用可能なインクベースのデータモデルを実現
- 生体データの保存メカニズム
- スプラインデータの保存メカニズム
- レンダリング設定の保存メカニズム
- インクモデルに含まれるスプライン/生の入力に基づいて論理ツリーを作成する機能
- 一般的な業界規格に合わせて変換できるため、高い移植性が実現
- インクデータに関連するセマンティックメタデータを記述できることにより、高い拡張性を実現
- 標準化されたシリアル化メカニズム
本参考ドキュメントでは、インクモデルのシリアル化に使用するRIFF container とProtocol Buffers schema に加え、インクモデルのさまざまなパーツ間の関係や、インクモデルのパー�ツと外部エンティティとの関係を記述する標準的な仕組みについて説明します。 詳細については、エンコードセクションをご確認ください。
指定されているシリアル化スキーマは、次の規格に基づいています。
- Resource Interchange File Format (RIFF) - タグ付きチャンクにデータを保存するための一般的なファイルコンテナ形式
- Protocol Buffers v3 - 構造化データをシリアル化するための言語非依存、プラットフォーム非依存の拡張可能なメカニズム
- Resource Description Framework (RDF) - ウェブ上でのデータ交換を実現する標準モデル
- OWL 2 Web Ontology Language (OWL2) - 形式的に定義された意味によってセマンティックウェブを実現するオントロジー言語
データモデル
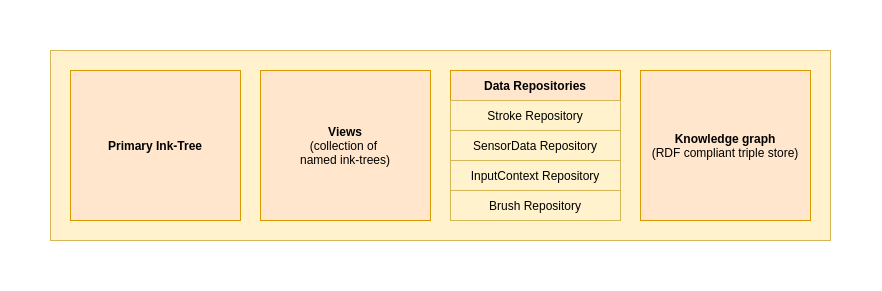
Universal Ink Modelには、5つの基本カテゴリがあります。
- 入力データ: データリポジトリ、保持している生のセンサー入力、入力デバイス/プロバイダ構成、センサーチャンネル構成などの集合のこと。それぞれのデータリポジトリは、特定のデータセットを隔離させた状態で保持し、固有のタイプのデータを担当します。
- インクデータ: デジタルインクの視覚的な表示内容であり、描画設定を有するインクジオメトリとして提示されます。
- メタデータ: 環境、入力デバイスなどに関連する付加的データのこと。
- インクツリー/ビュー: 論理ツリーの集合のことで、階層的に体系化されたパスや生の入力データフレームの構造を表します。
- セマンティックトリプルストア - RDFに準拠したトリプルストアであり、テキスト構造、手書き認証結果、セマンティックエンティティなどのセマンティック情報を保持します。
下の図は、インクモデルの各種論理要素を示しています。
このUML図(click here) は、論理モデルとクラスの依存関係の観点からInk Model全体を示しています。 次の現在の仕様に関するセクションでは、Ink Modelの各種論理要素について詳細に説明しています。
Universal Ink Modelは@@@を使用してシリアル化されます。 protobuf message InkObject.
Universal Ink Modelを使用すると、単なるペンデータの表示だけでなく、さまざまなアプリケーションに柔軟に対応できるようになります。 たとえば、データマイニングやサインの比較にも同じデータを使用したり、縮尺調整や表示形式の調整が必要となるさまざまなプラットフォーム上でインクを表示したりできます。
入力データ
実際には、ペンデータは位置を表す点群としてペンデバイスから取得されます。

ハードウェアのタイプによっては、これらの点にX/Yの位置座標だけでなく、ペン先の力や角度などの追加情報を持たせることができます。 この情報は集合的にセンサーデータと呼ばれており、Universal Ink Modelでは入手可能なデータのすべてを保存することができます。 たとえば、ペンが書き込み面に接触していない間にペンホバー座標を取得できるタイプのハードウェアもあります。 こうした情報はUniversal Ink Modelに保存され、必要な際に使用することができます。
インクデータ
WILL処理の重要な機能は、ペンデータのレンダリングです。 ペンの筆跡(ストローク)は、ペンが書き込み面に接している間に取得される連続したペン座標群として識別されます。たとえば、文字「w」を書く場合は下に示すとおりです。 このプロセスでは、それぞれのペンストロークを数学的表現に変換してから、これを使用してディスプレイ上にその形をレンダリングすることができます。 下にいわゆるInk Geometry pipelineのステップが示されていますが、それぞれのステップをアプリケーションで設定して必要な出力を生成します。

その結果、データ点は平滑化され、目的の表現を生むよう形成されます。たとえば、フェルトペンの見た目を模倣できま��す。 レンダリングブラシタイプの選択では、ラスターレンダリングとベクトルレンダリングがサポートされています。
結果は、インクジオメトリとレンダリング情報を含むインクデータとして保存されます。
メタデータ
メタデータは、ペンデータについてのデータとして追加されます。 Universal Ink Modelは、作者名、場所、ペンデータソースなどの管理情報に対応しています。 他のメタデータはペンデータの解析によって計算されます。 以下では、デジタルインクの例に注釈を付けています。
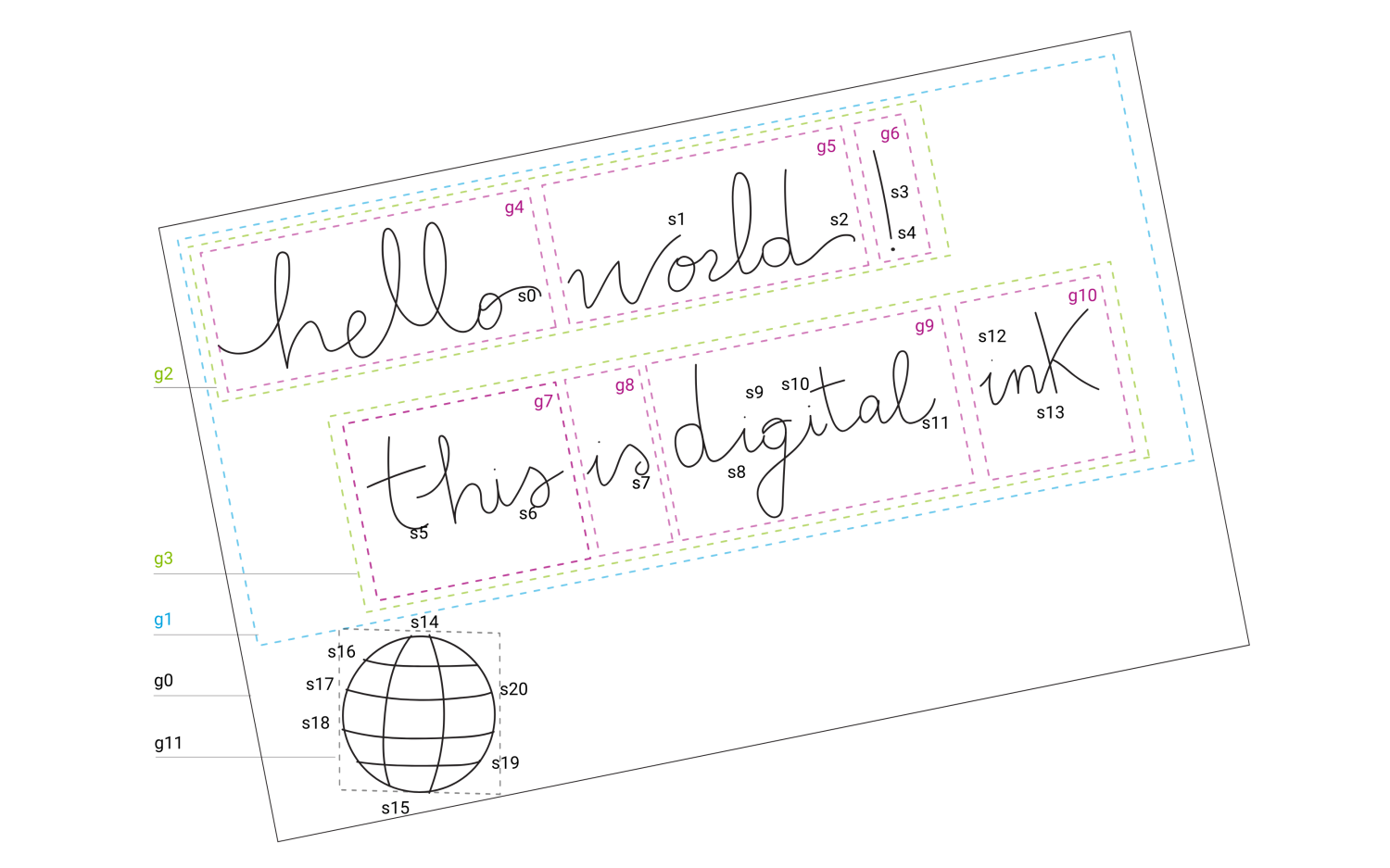
ペンストロークはs1、s2、s3などのラベルによって識別されます。 さらに、ストロークのグループをg1、g2、g3などとして特定しています。 ペンストロークは手書き認証エンジンに渡され、その結果はセマンティックデータと一般的に呼ばれる追加のメタデータとして保存されます。 セマンティックデータは、単一の文字、個々の単語、テキスト行などと分類されるグループを基準として保存されます。