Universal Ink Model
This documentation covers version 3.0.0 of the Universal Ink Model. For information on version 3.1.0 of the Universal Ink Model, click here.
This specification defines a language-neutral and platform-neutral data model for representing and manipulating digital ink data captured using an electronic pen or stylus, or using touch input. This data model is referred to as the "Universal Ink Model" within this documentation.
The main aspects of the ink model are:
- Interoperability of ink-based data models by defining a standardized interface with other systems
- Biometric data storage mechanism
- Spline data storage mechanism
- Rendering configurations storage mechanism
- Ability to compose spline/raw-input-based logical trees, which are contained within the ink model
- Portability, by enabling conversion to common industry standards
- Extensibility, by enabling the description of ink data-related semantic metadata
- Standardized serialization mechanism
This reference document defines a RIFF container and Protocol Buffers schema for serialization of ink models as well as a standard mechanism to describe relationships between different parts of the ink model, and/or between parts of the ink model and external entities. For further details check the encoding section.
The specified serialization schema is based on the following standards:
- Resource Interchange File Format (RIFF) - A generic file container format for storing data in tagged chunks
- Protocol Buffers v3 - A language-neutral, platform-neutral extensible mechanism for serializing structured data
- Resource Description Framework (RDF) - A standard model for data interchange on the Web
- OWL 2 Web Ontology Language (OWL2) - An ontology language for the Semantic Web with formally defined meaning
Data Model
The Universal Ink Model has five fundamental categories:
- Input data: A collection of data repositories, holding raw sensor input, input device/provider configurations, sensor channel configurations, etc. Each data repository keeps certain data sets isolated and is responsible for specific type(s) of data
- Ink data: The visual appearance of the digital ink, presented as ink geometry with rendering configurations
- Metadata: Related meta-data about the environment, input devices, etc.
- Ink Trees / Views: A collection of logical trees, representing structures of hierarchically organized paths or raw input data-frames
- Semantic triple store - An RDF-compliant triple store, holding semantic information, such as text structure, handwriting recognition results, and semantic entities
The diagram below illustrates the different logical parts of the ink model.
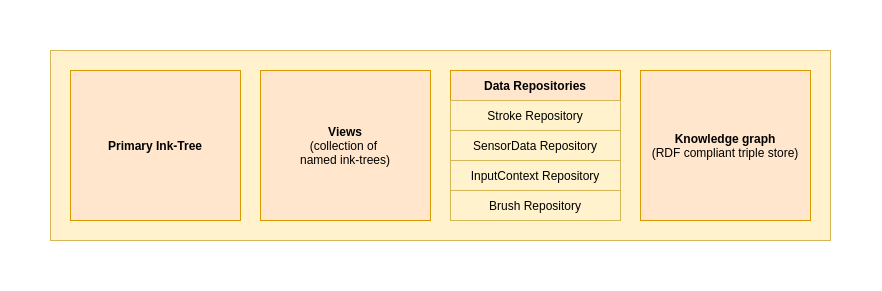
This UML diagram (click here) illustrates the complete Ink Model in terms of logical models and class dependencies. In the next sections of the current specification, the different logical parts of the Ink Model are described in detail.
The Universal Ink Model is serialized using the protobuf message InkObject.
The Universal Ink Model provides the flexibility required for a variety of applications, since the display of pen data is only one aspect. For example, the same data can be used for data mining or even signature comparison, while the ink display can be on a range of platforms potentially requiring different scaling and presentation.
Input data
In reality, pen data is captured from a pen device as a set of positional points:

Depending on the type of hardware, in addition to the X/Y positional coordinates, the points can contain further information such as pen tip force and angle. Collectively, this information is referred to as sensor data and the Universal Ink Model provides a means of storing all of the available data. For example, with some types of hardware, pen hover coordinates can be captured while the pen is not in contact with the surface. The information is saved in the Universal Ink Model and can be used when required.
Ink data
A significant function of WILL processing is the rendering of pen data. Pen strokes are identified as continuous sets of pen coordinates captured while the pen is in contact with the surface. For example, writing the letter ‘w', as illustrated below. The process converts each pen stroke into a mathematical representation, which can then be used to render the shape on a display. Steps in the so-called Ink Geometry pipeline are illustrated below where each step is configured by an application to generate the desired output:

As a result, the data points are smoothed and shaped to produce the desired representation. For example, simulating the appearance of a felt-tip ink pen. Raster and vector rendering is supported with a selection of rendering brush types.
The results are saved as Ink data, containing ink geometry and rendering information.
Metadata
Metadata is added as data about the pen data. The Universal Ink Model allows for administrative information such as author name, location, pen data source, etc. Further metadata is computed by analysis of the pen data. An example of digital ink is annotated below:
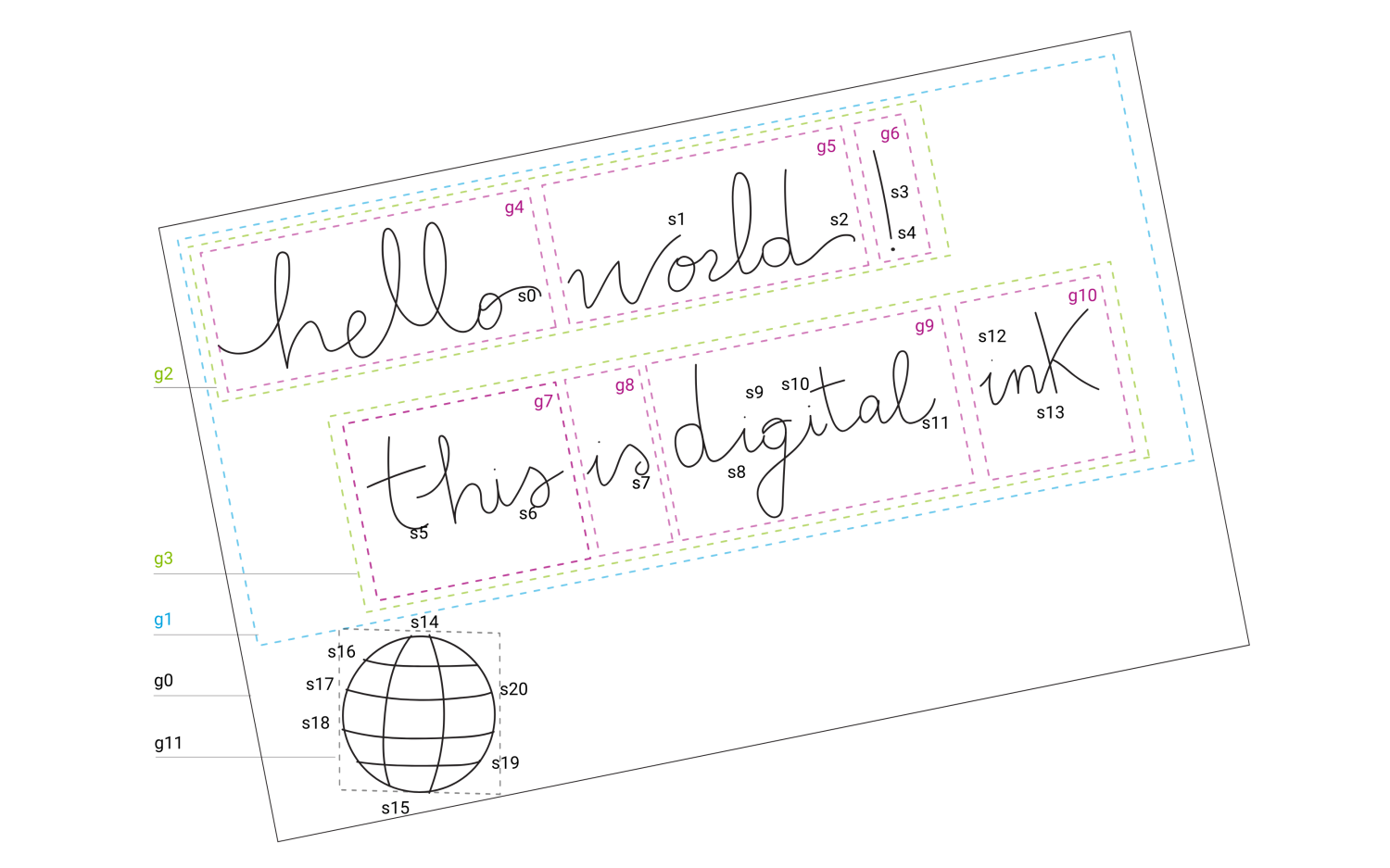
The labels identify pen strokes s1, s2, s3, etc. In addition, groups of strokes are identified as g1, g2, g3, etc. Pen strokes are passed to a handwriting recognition engine and the results are stored as additional metadata, generally referred to as semantic data. The semantic data is stored with reference to the groups, categorized as single characters, individual words, lines of text, and so on.