语义学
墨水语义语句分配的核心结构是分组机制。 在大多数情况下,单笔墨水笔划不包含有意义的信息,只有笔划集合或一组笔划才包含有意义的信息,如图1所示,其中,笔划s8、s9、s10和s11构成了单词*“digital”。 组按照行业标准树数据结构进行处理,保存了一组墨水笔划节点及相关传感器数据。 例如,在图2*中,g4是单词“hello”,g5是“world”,g6是标点符号“!”。 它们组成g2,代表一个段落中的一个文本行。 富文本编辑中采用相似的结构机制,这里它应用于墨水文档。
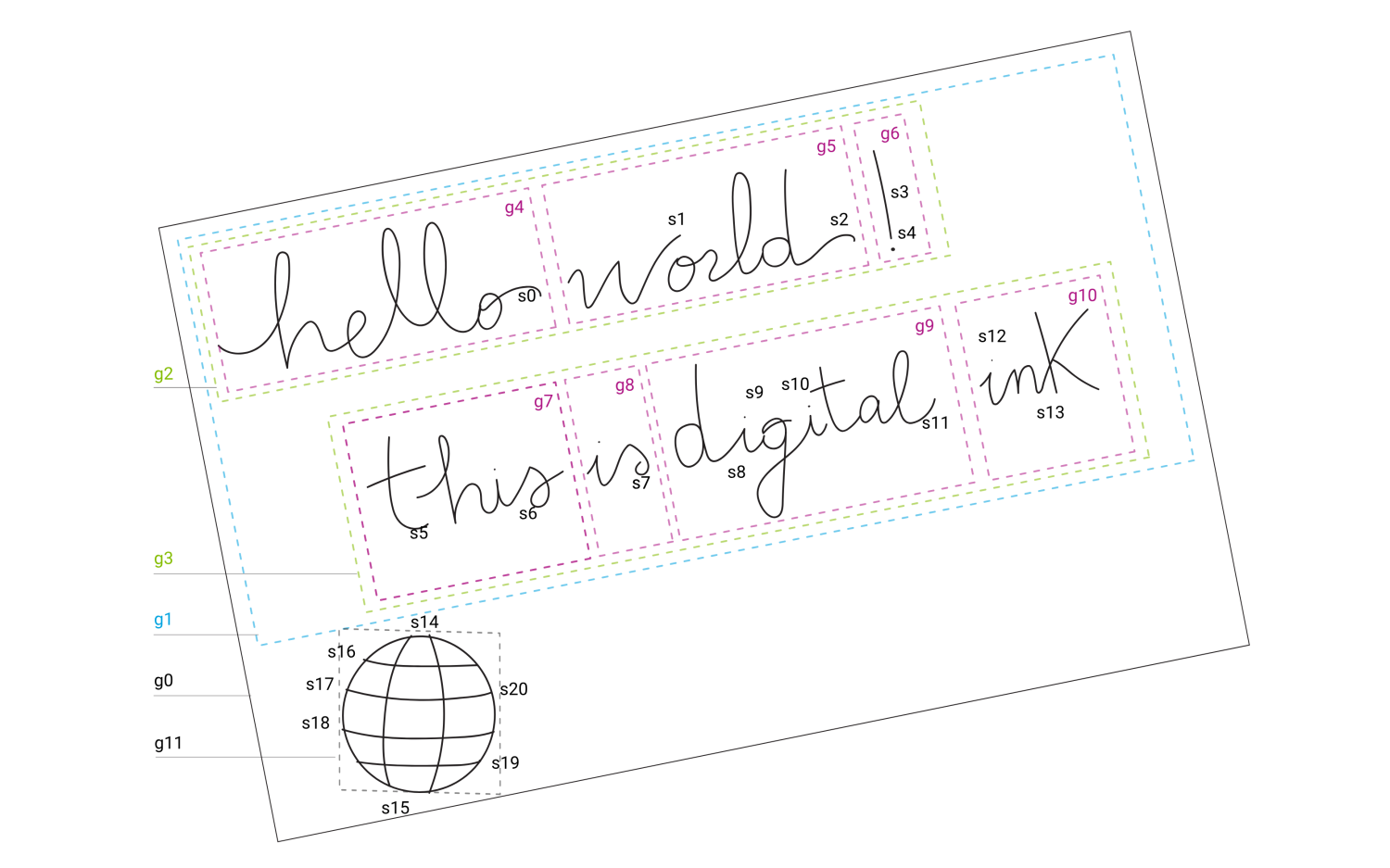
图1:带组的墨水文档实例
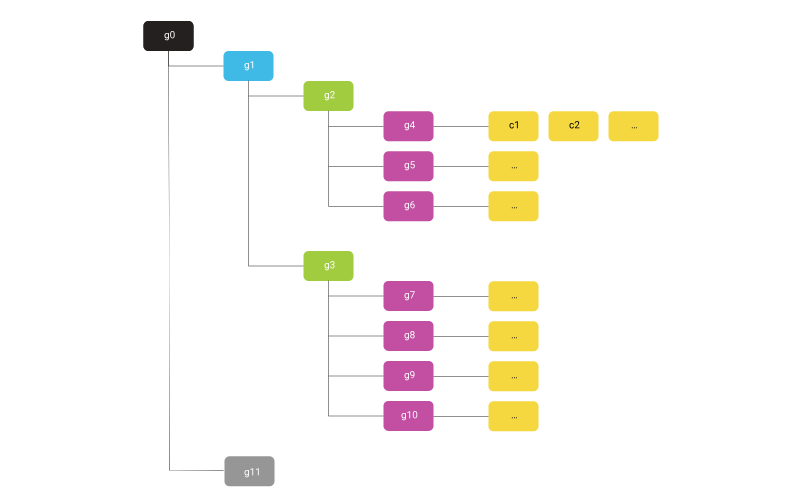
图2:组的分级结构
墨水组由一系列元素组合而成,它们可以是:
- 传感器数据序列
- 墨水路径
- 数据块RAW 传感器数据 或
- 墨水路径数据块
在Universal Ink Data format中,使用基本概念保存墨水组的语义内容。 图3展示了语义语句如何与墨水组相链接,对于图1中的实例,可写出下列语义语句:
- g2 - is_a TEXTLINE
- g2 - has_text "hello world!"
- g2 - is http://dbpedia.org/page/%22Hello,_World!%22_program
因此,应用接收到这些富含语义内容的墨水后,可理解墨水文档的内容。
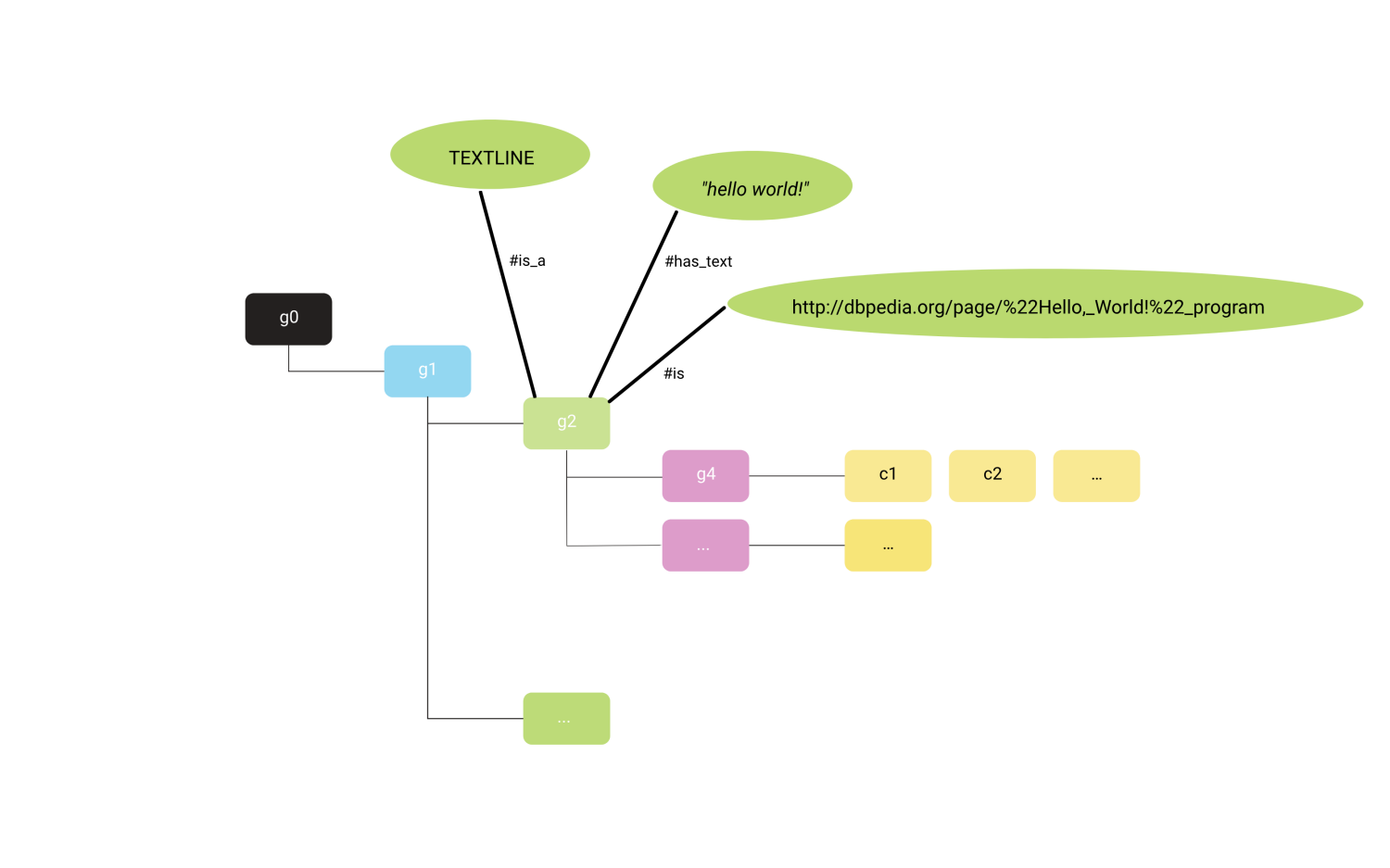
图3:分配给墨水组的语义实例。
Ink Model可能保有一个逻辑树(InkTree),它表示了层级路径或原始输入数据框架的结构。 该树也被称为主墨水树或一级墨水树。
Ink Tree
InkTree被定义为节点的有序逻辑树,即,墨水节点。(InkNode). 它用于表示路径或原始数据框架的层级结构。
说明:
在该层级结构中,单个InkTree被称为Path或SensorData对象。 墨水树实例由其根节点(详细信息请参见InkNode的定义)定义;因此,InkTree实例使用protobuf message Node.
InkNode进行序列化
墨水树的逻辑节点。 根据类分级结构,InkNode应被认为是抽象类,具体归类为下列类:
- PathNode - 树叶节点,保有到路径的引用,由Path数据库提供
- ensorDataNode - 树叶节点,保有到SensorData实例的引用,由SensorData数据库提供
- InkGroupNode (abstract) - 非树叶节点,用于给其他墨水节点分组;具体归类为:
- PathGroupNode - 非树叶节点,用于给PathNode和/或PathGroupNode类型的墨水节点分组
- SensorDataNode - 非树叶节点,用于给SensorDataNode和/或SensorDataGroupNode类型的墨水节点分组
说明:
在InkModel范围中,InkNode标识符是唯一的。 InkNode实例使用protobuf message Node.序列化
Ink Model可能还保有墨水数据 (InkView)的视图集合,以具名墨水树集合的形式保存。 这些视图代表墨水模型不同的方面,例如,文本分段视图、具名实体识别视图等。
InkView
InkView被定义为具名墨水树。
说明:
InkView的实例名称在InkModel范围内是唯一的,被编码为URI。关于已知视图的定义,请参见第C3节。常规InkModel视图。 视图实例使用protobuf message View.
Knowledge Graph序列化
Ink Model规范提供一个标准机制,描述ink model不同部分之间和/或墨水模型和外部实体之间的关系。 Ink Model保留一个兼容RDF三元组表存储的实例,在本文档中称为"Knowledge Graph"。 该三元组表存储包含一个语义三元组表的列表,它根据RDF规范中的定义,对主语、谓语和宾语之间的关系进行编码。
使用墨水模型中墨水视图的知识图谱节点,可使用附加元数据进行注解,以便描述墨水模型的不同方面,例如,文本分段视图、具名实体识别视图等。
Knowledge Graph,兼容RDF的三元组表存储,由语义三元组表实例来表示。
说明:
InkModel中包含的逻辑树的节点,在三元组表存储中,按照第vocabulary.节中的指南,以URIs进行标识 知识图谱实例使用protobuf消息TripleStore.
SemanticTriple序列化
兼容RDF的三元组表,包括:
- 主题
- 谓语
- 宾语
RDF数据模型与经典的概念建模方法类似(例如,实体关系或类图)。 它基于以主谓宾(即三元组表)的形式进行资源(特别是Web资源)语句声明的理念。 主语指定资源,谓语(也称为三元组表的属性)指定资源的特性或方面,以及表达主语和宾语之间的关系。
说明:
Knowledge Graph实例使用protobuf message SemanticTriple序列化。