Universal Ink Model
该规范定义了独立于语言和平台的数据模型,用以表达和操控使用电子笔或触控笔或使用触摸输入捕获的数字墨水数据。 在本文档中,该数据模型被称为"Universal Ink Model"。
墨水模型主要的方面包括:
- 通过定义与其他系统的标准化接口,墨水基于数据模型的互操作性
- 生物学数据存储机制
- 样条数据存储机制
- 渲染配置存储机制
- 基于样条/原始输入的构建逻辑树(包含在墨水模型中)的能力
- 可移植性,能够转换为普通工业标准
- 可扩展性,启用与墨水数据相关的语义元数据描述
- 标准化的序列化机制
该参考文档定义了墨水模型序列化的
专门的序列化方案基于下列标准:
- Resource Interchange File Format (RIFF) - 用于在标签化数据块中存储数据的通用文件容器格式
Protocol Buffers v3 - 序列化结构数据的独立于语言、平台的可扩展机制- Resource Description Framework (RDF) - 用于Web上数据交换的标准模型
- OWL 2 Web Ontology Language (OWL2) - 包含正式定义含义的语义Web的本体语言
数据模型
Universal Ink Model 有五个基本类别:
- 输入数据: 数据库集合,包含原始传感器输入、输入设备/提供者配置、传感器通道配置等。每个数据库都保持特定的数据集相互隔离,分别负责特定的数据类型
- 墨水数据: 数字墨水中视觉外观,以包含渲染配置的墨水几何形状表示
- 元数据: 关于环境、输入设备等的相关元数据
- 墨水树/视图: 逻辑树集合,描述层级组织路径或原始输入数据框架的结构
- 语义三元组存储 - 兼容RDF的三元组表存储,包含语义信息,例如,文本结构、手写识别结果和语义实体等
下图给出了墨水模型的不同逻辑部分。
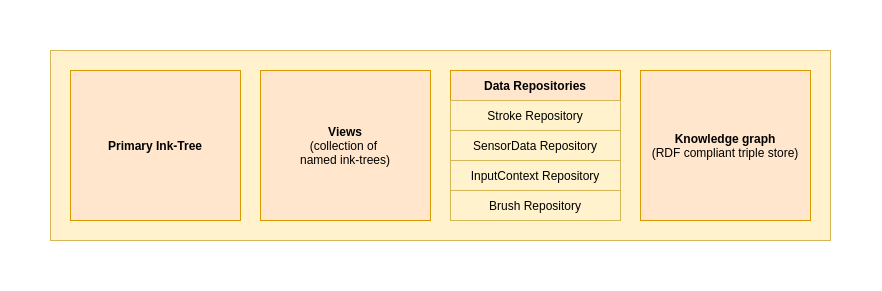
该UML图
Universal Ink Model使用protobuf message InkObject.进行序列化
Universal Ink Model提供各种应用所需的灵活性,这是因为笔数据的显示只是一个方面。 例如可以将相同的数据用于数据挖掘甚至签名比对,同时,墨水显示可以在需要不同缩放和呈现的一系列平台上进行。
输入数据
实际上,笔数据以一组位置点的形式从笔设备上捕获。

根据硬件类型,除了X/Y位置坐标以外,点还可包含许多信息,例如,笔尖的力和角度。 该信息被统称为传感器数据,Universal Ink Model提供一种存储所有可用数据的方法。 例如,对于一些数据类型,可捕获笔未接触表面的悬停坐标。 该信息保存在Universal Ink Model中,可根据需要使用。
墨水数据
WILL处理的一项重要功能时渲染笔数据。 笔的笔划通过笔接触表面时捕获到的连续笔坐标集来识别。例如,书写字母“w”,如下图所示。 过程将每个笔划转换成数学表达式,可用它在显示屏上渲染形状。 所谓的Ink Geometry pipeline中的步骤如下所示,其中,每个步骤都由一个应用程序配置,生成所需的输出:

从而,数据点被平滑和整形,生成所需的表达式。例如,模拟签字笔的外观。 光栅和矢量渲染通过一组渲染刷子类型支持。
结果保存为墨水数据,包括墨水几何图形和渲染信息。
元数据
元数据是关于笔数据的数据。 Universal Ink Model提供管理信息,例如,作者名字、位置、笔数据源等。 更多元数据通过分析笔数据计算得到。 数字墨水的实例如下所示:
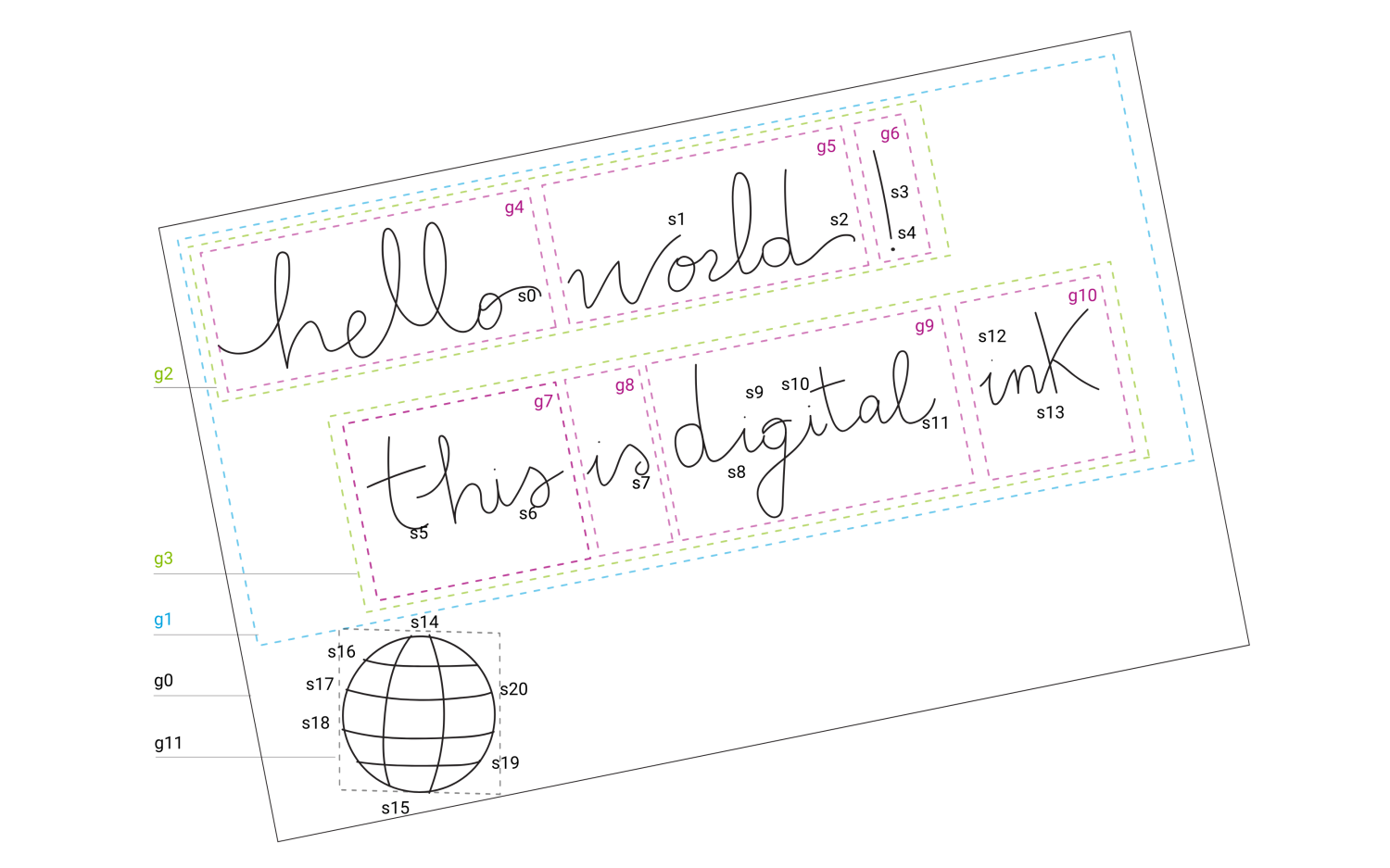
标签标识笔笔划s1、s2、s3等。 此外,笔划组标识为g1、g2、g3等。 笔划被传送到手写识别引擎,结果被保存为附加元数据,通常被称为语义数据。 语义数据以组的形式存储,归类为单个字符、单个字、文本行等等。